


红桃视频88热门电视剧全集流畅播放无广告向深空再出发
2025-04-03 19:51:41
来源:新华社




新华社北京4月1日电 记者手记:“月”向深空再出发
新华社记者刘祯、宋晨
“古人望月抒怀,我们揽月而归!”
“每一件展品都是中国航天人的军功章。”
“同时看到嫦娥五号、六号取回的月球正、背面月壤,非常自豪。”
在中国国家博物馆举行的“九天揽月——中国探月工程20年”展览现场,人们围在一件件展品前,发出阵阵赞叹。
当记者走进以蓝色为主色调的展厅,犹如飞翔在神秘浩瀚的宇宙。一件件展品、一张张照片、一帧帧影像,通往几代航天工作者用奋斗铺就的探月之路。
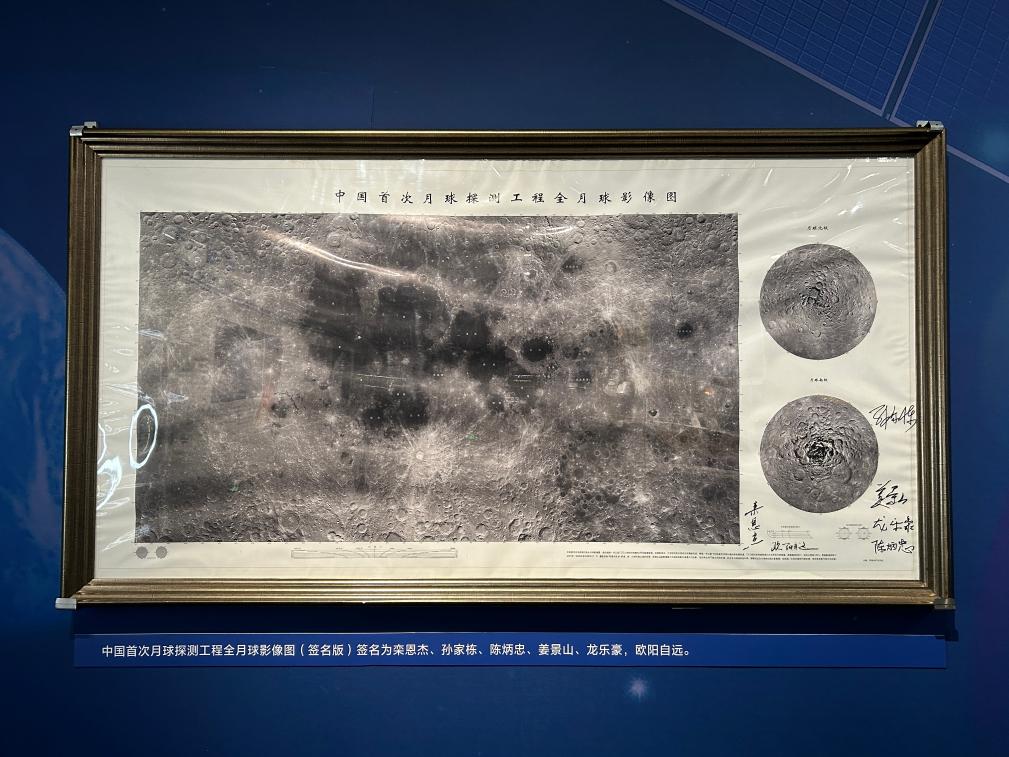
这是展览现场展出的中国首次月球探测工程全月球影像图(签名版)。新华社记者刘祯 摄
绕月——
2007年,嫦娥一号成功实现绕月飞行,获取首幅全月图。如今,这幅中国首次月球探测工程全月球影像图,就在眼前。这张照片不仅有月表图像,还呈现了月球的地形地貌数据,成为了当时世界上公布的月球影像图中最完整的一张。
落月——
“广寒宫里有嫦娥,也有玉兔啦!”一位前来参观的小朋友指着嫦娥三号与“玉兔号”月球车的一组图片,兴奋不已。
2013年,嫦娥三号携“玉兔号”月球车成功着陆月球。随后,“玉兔号”月球车分离到月球表面,移动到合适位置后,和嫦娥三号着陆器互为“摄影师”,为对方拍下珍贵的“月球打卡照”。
揽月——
透过放大镜、显微镜,来自38万公里外的月壤岩屑、粉末,一览无余。
2020年,嫦娥五号达成月球采样返回的壮举。2024年6月25日,嫦娥六号携带1935.3克月球背面样品返回地球,实现人类首次月球背面采样返回。
“这是人类历史上第一次有机会同时近距离对比观看月球正面和背面的样品。”年逾七旬的中国探月工程总设计师吴伟仁面对展品,难掩激动之情。

这是展览现场展出的嫦娥六号岩屑样品和嫦娥六号粉末样品。新华社记者刘祯 摄
20年筚路蓝缕,中国探月圆满完成“绕、落、回”三步走规划,创造了多个“世界首次”,实现了从无到有,从小到大,从弱到强的历史性跨越。
“这些成就不仅填补了人类探月空白,更让中国航天从‘跟跑者’成为‘并行者’甚至‘领跑者’。”吴伟仁说,一代代航天人胸怀国之大者,勇攀科技高峰,凝聚形成了“追逐梦想、勇于探索、协同攻坚、合作共赢”的探月精神。
月球,这颗距离地球最近的天体,到底什么样?全人类望向苍穹的好奇与中国古人寄托情志的婵娟遥想,都在20年的脚步中,融入建设航天强国、科技强国的壮丽篇章。
从一曲“东方红”响彻太空,到“嫦娥”奔月化作现实,记者驻足于一件件展品前,流连在壮阔的时空中,耳畔回响着吴伟仁总师的话语。
“我们要把这份精神化作仰望星空的初心、脚踏实地的行动、敢为天下先的勇气、万人一杆枪的协作,不断地逐梦星空、探索未知。”
探月之旅还将继续,更多奇迹等待创造。





